前段时间看到很多爬虫的案例,有很多爬招聘网站数据的,还有房产中介数据的,当然也有很多爬取知乎用户数据的,很多爬虫都是用Python语言,但是我不会用它,只能用Java写一个爬虫来抓取知乎问题下答案的图片链接
先上一个下载的图片的截图
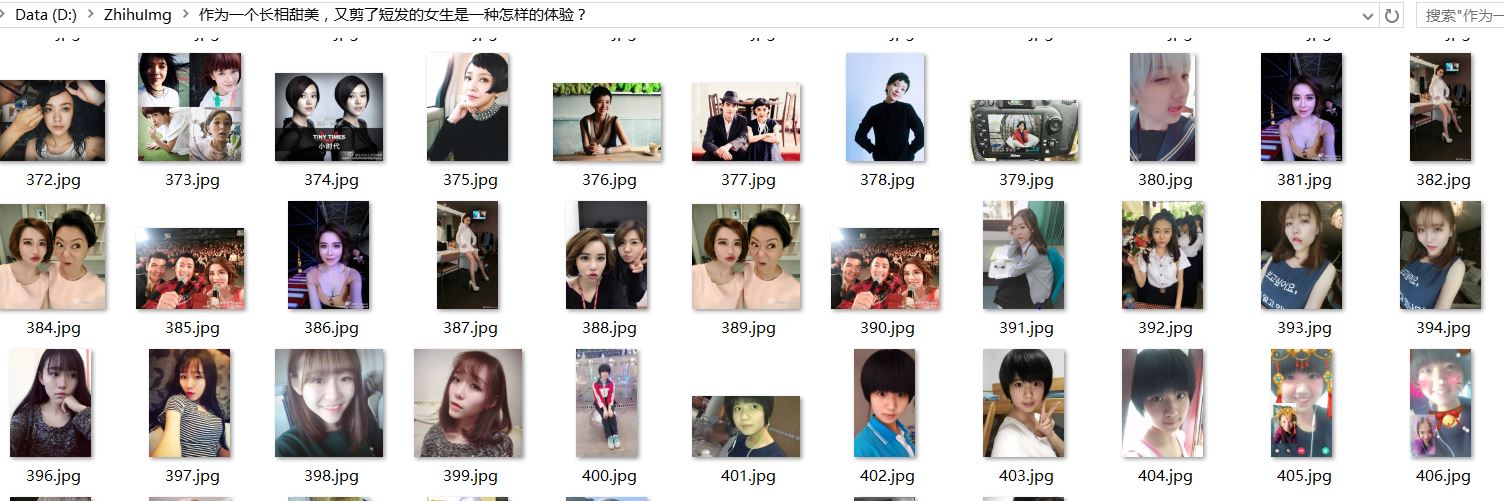
看到网上这么多人写爬虫,心里也是羡慕,想着自己什么时候也可以写一个简单的爬虫来了解下爬虫的原理,这几天刚开学,就尝试来抓取知乎的图片,主要是因为知乎某些问答的妹子都很好看……
抓取的原理
想办法获取图片的链接,然后添加到一个容器中,依次下载,很简单的
过程
一开始我单纯的认为只要获取一个问答首页的源码,然后用正则表达式拿到图片链接,接下来就不是事儿了。但是这样做只能获取到第一页的数据
下图为第一页的数据,每一个List-item就是一个回答,这儿一共才20条

点击查看更多回答。F12中打开network选项卡,再选择XHR查看AJAX请求,发现有一个链接特别长,查看request和response,就发现了下图中的东西
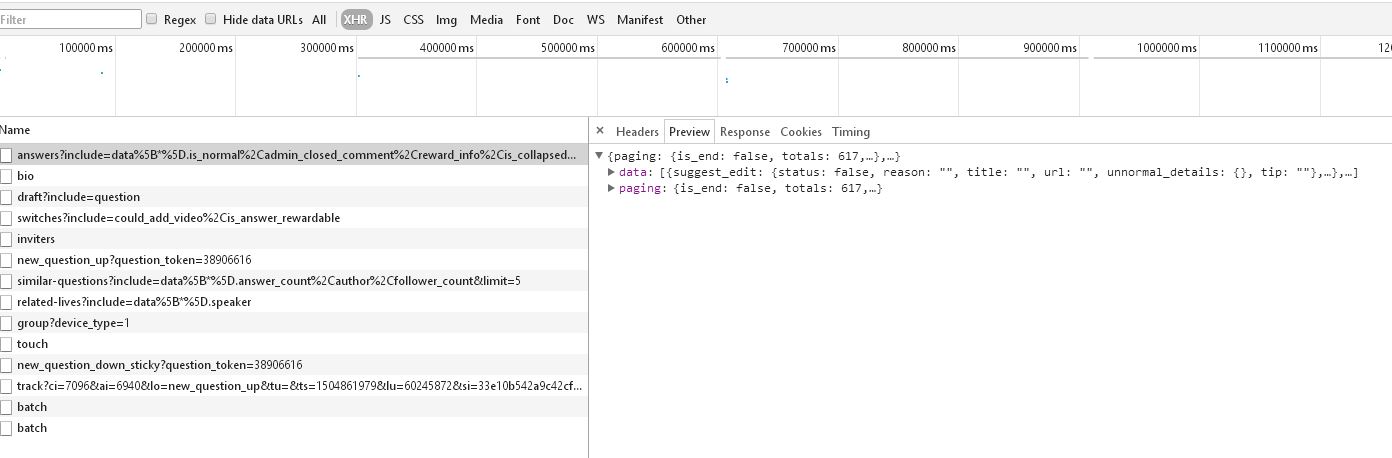
查看请求的详情,发现这个请求返回的是一个json数据

这是一个实例链接:https://www.zhihu.com/api/v4/questions/38906616/answers?include=data%5B*%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cupvoted_followees%3Bdata%5B*%5D.mark_infos%5B*%5D.url%3Bdata%5B*%5D.author.follower_count%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=3&limit=20&sort_by=default
链接参数中的offset表示与第一个回答的偏移量,limit表示返回回答数据的条数
我以为这样就可以了,用在线get工具测试了一下,看是不是相同的结果
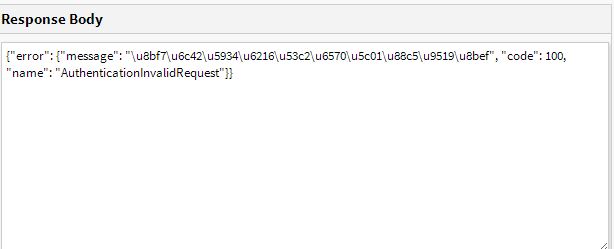
结果响应了这样的json数据,根据那个英语,猜测是没有授权,于是去浏览器开发人员工具下寻找有没有什么特殊request的Header没有添加,于是发现了一个authorization的字段,故添加好header参数后再次尝试,结果呢?这次就对了
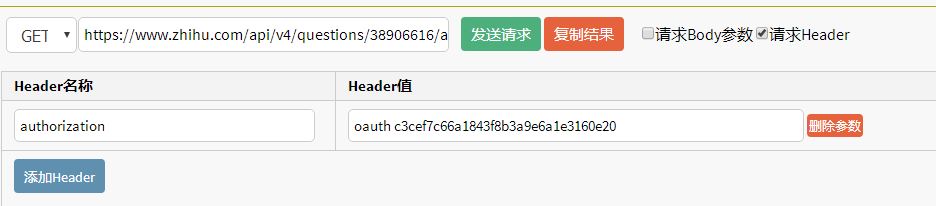
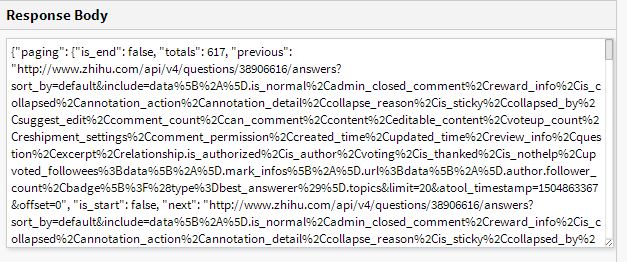
如果问这个authorization字段的值怎么来的,其实我也不知道,我是复制的浏览器的数据
现在拿到了回答的json数据
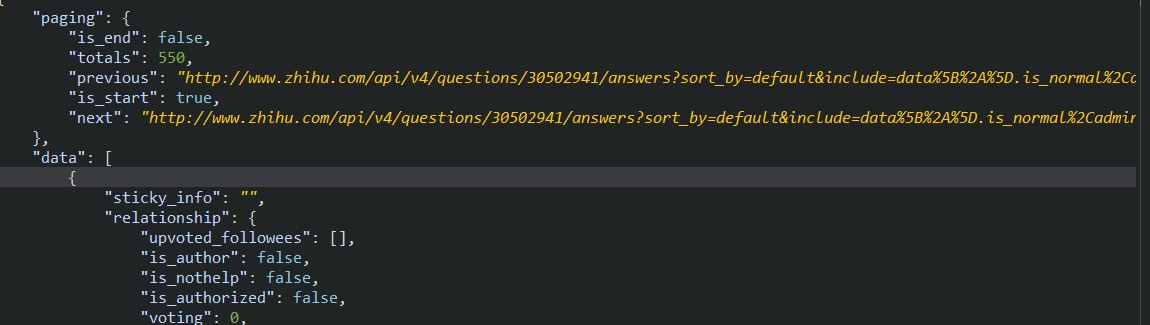
经过分析,每一个回答的json中有一个content属性,这个属性包含了回答的内容,其中就含有图片的链接。到此,感觉寄几终于找到了光明

通过这个属性的值,就可以拿到图片的链接。
返回的这个json数据中还包含回答的总数等内容,更多有用的就自己去挖掘了哟
使用的jar包:
httpclient
json-lib:解析json数据
使用这些jar包还需要其它依赖包
需要注意的地方
- 这个小项目中没有登录,所以有的需要登录账号的问题就不能获取到图片链接,会跳转到登录的页面
- 图片较多的时候下载时间会比较长,没有使用多线程技术
最后附上项目的github地址Java抓取知乎图片